SEO Experiment Design for Production Page Changes
Last reviewed: 2026-05-10. This is a deep EskiLab implementation guide for SEO experiment design. It is written for teams that need operational reliability, not a surface-level definition.
SEO experiments are noisy. That is why they need cleaner design, not bigger claims.
What this guide is designed to do
This guide helps teams test SEO changes without making random production edits that cannot be measured or rolled back. It focuses on the operating decisions behind the system: ownership, data contracts, failure modes, QA scenarios, monitoring, and the point where automation should stop and review should begin.
Who should use this
Seo operators, content teams, agencies, site owners, and technical marketers managing pages with organic search value should use this as a production planning and QA reference. It is especially relevant when the workflow affects customers, analytics, public pages, revenue, product data, or long-running automation.
Executive summary
A reliable SEO experiment design system defines the operating contract, validates inputs before action, tests failure modes, monitors drift after launch, and documents ownership so the workflow can be maintained without guesswork.
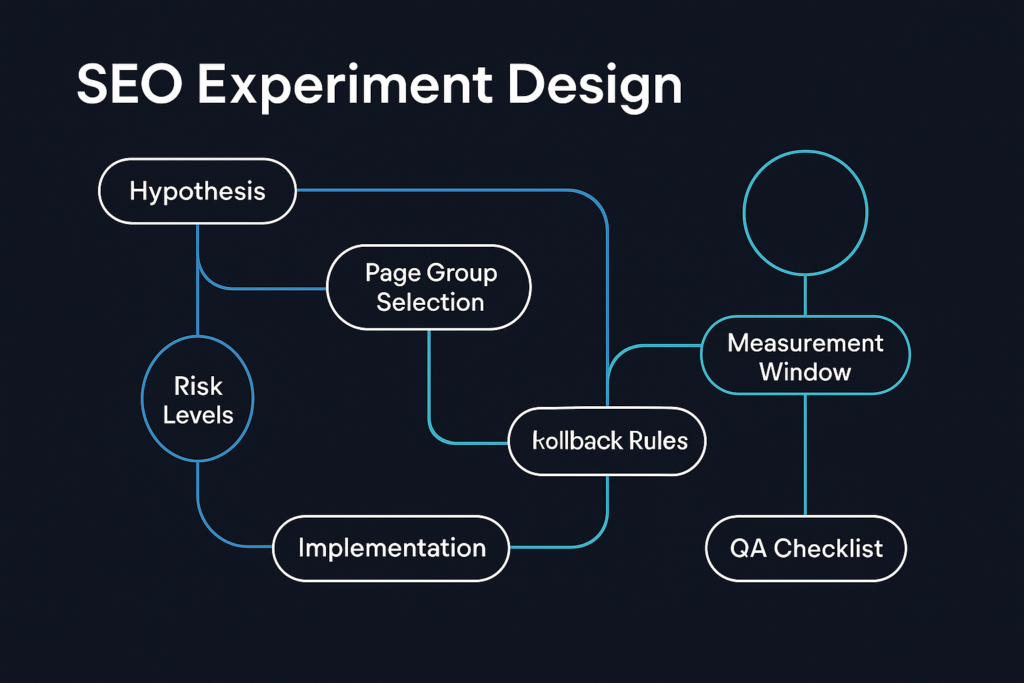
One hypothesis, one primary change
An SEO experiment should begin with a sentence: changing X on pages like Y should improve Z because of reason W. If you cannot write that sentence, you are not running an experiment; you are editing.
Keep the primary change narrow. A title test, content expansion test, internal link test, or schema test can each be useful. Combining all of them makes it harder to know what moved the result.
Page group selection
Do not start with your most valuable pages. Start with a relevant page group that has enough impressions to measure but low enough risk to tolerate uncertainty. The pages should share intent, template, and baseline behavior.
If possible, keep a comparable group unchanged. SEO is not a perfect lab, but a comparison group helps prevent overreacting to seasonality, algorithm updates, news cycles, or general site movement.
Measurement window and rollback
Search data is delayed and noisy. Define the measurement window before launch, often 28 days or longer depending on query volume. Also define the rollback condition before emotions enter the decision.
Store old titles, content blocks, internal links, and schema settings. Rollback is hard when nobody saved the original.
Experiment plan fields
| Field | Purpose | Example |
|---|---|---|
| hypothesis | Defines what is tested | Clearer titles improve CTR |
| page_group | Limits scope | 20 API troubleshooting posts |
| primary_metric | Measures outcome | CTR from Search Console |
| change_log | Preserves old/new values | old title and new title |
| decision_rule | Prevents emotional changes | keep if CTR improves after 28 days |
Experiment risk levels
| Change | Risk | Start where |
|---|---|---|
| Meta description | Low | Low-risk pages |
| Title format | Medium | Comparable page group |
| Content rewrite | Medium/high | Pages with decay |
| Template internal links | High | Small rollout |
| Canonical/indexation | High | Technical staging and sample |
Implementation workflow
- Write the hypothesis.
- Select a page group with similar intent.
- Choose one primary metric.
- Save old values before changes.
- Apply one primary change type.
- Record date, URLs, and expected outcome.
- Wait through the measurement window.
- Decide keep, rollback, expand, or retest based on predefined rules.
Common mistakes that make this system shallow
- Changing title, content, schema, and links at once.
- Testing one page and calling it proof.
- Judging after two days.
- Not saving old values.
- Ignoring seasonality or algorithm changes.
- Expanding before checking side effects.
Pre-production QA checklist
- [ ] Hypothesis is written.
- [ ] Page group is defined.
- [ ] Old values are saved.
- [ ] Primary metric is selected.
- [ ] Measurement window is defined.
- [ ] Rollback rule exists.
Monitoring signals after launch
Do not judge the system only by whether the first test worked. Use ongoing monitoring to detect drift, silent failure, and operational risk.
- clicks
- impressions
- CTR
- average position
- query mix changes
- conversion or engagement where relevant
Incident review questions
- What exact input, event, URL, record, prompt, or action triggered the failure?
- Was the failure caused by source data, mapping, permissions, timing, platform behavior, or missing validation?
- Did the system fail safely, or did it create a downstream side effect?
- Was the issue visible in logs or only discovered by a user?
- What rule, test case, monitor, or approval step should be added so this failure is easier to catch next time?
Official documentation to check
Recommended operating standard
For SEO experiment design, the minimum operating standard is: define the contract, test the failure modes, monitor the output, document the owner, and keep a rollback or review path. Anything less may work in a demo but will be fragile in production.
FAQ
Why is SEO experiment design not just a one-time setup?
Because the surrounding systems change: APIs, tools, data, user behavior, plugins, prompts, feeds, and business rules. A one-time setup without monitoring becomes stale.
What is the first thing to test?
Test the failure mode that would create the most business damage: duplicate writes, wrong public pages, bad tracking, invalid feed data, unsafe AI action, or broken indexation.
Should this be automated completely?
Only low-risk, reversible steps should be fully automated. Anything that changes customer data, sends messages, publishes pages, affects payments, or modifies important SEO signals should have review, logging, or staged rollout.
How do I know the article's system is deep enough to publish?
It should include a real operating model: data fields or rules, failure modes, QA scenarios, monitoring signals, mistakes, and official documentation references.