Good API error handling is not just trying again. A reliable integration separates temporary failures from permanent failures, retries safely, avoids duplicates, and logs enough context to debug later.
What This Solves
This guide helps build API error handling for integrations that need to run reliably without duplicate records, silent failures, or retry storms.
Who This Is For
- Developers and technical operators
- SEO, automation, or e-commerce teams
- Site owners who need a repeatable workflow
- Editors or builders documenting technical systems
Short Answer
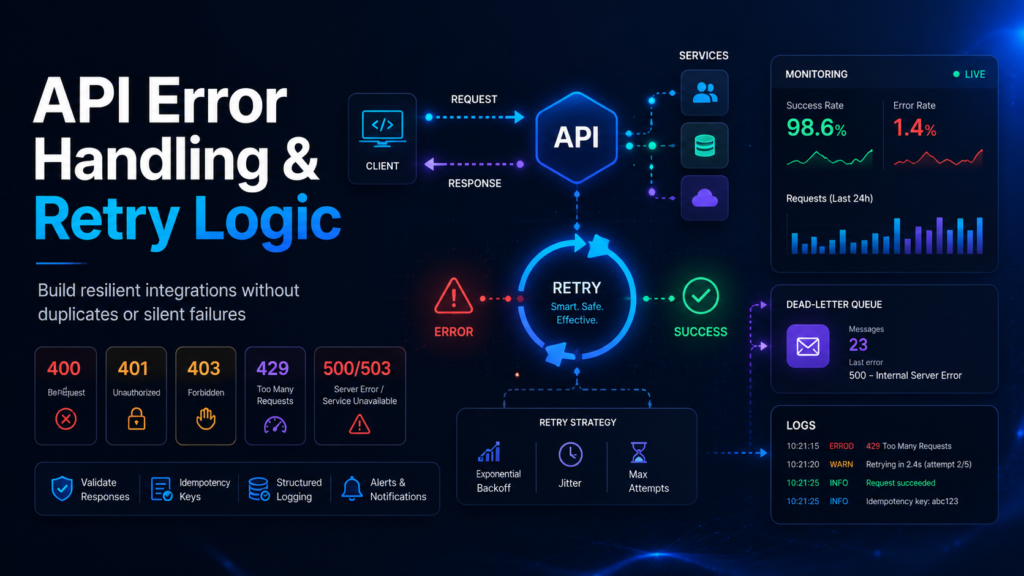
Classify errors by status code, retry only temporary failures, avoid retrying invalid requests, use idempotency for sensitive actions, and monitor error patterns.
When This Happens
API failures happen because of invalid input, authentication problems, rate limits, provider outages, network timeouts, or application bugs.
Root Causes
| Symptom | Likely Cause | What to Check |
|---|---|---|
| 400 response | Permanent request problem | Payload validation |
| 401 response | Authentication failure | Token and scopes |
| 403 response | Permission failure | Role and account access |
| 429 response | Rate limit | Retry-After and concurrency |
| 500/503 | Provider/server issue | Backoff and alerting |
Step-by-Step Fix or Implementation
- Group responses into retryable and non-retryable categories.
- Do not retry invalid payload errors without fixing data.
- Retry temporary server or network failures with backoff.
- Use idempotency keys where supported.
- Log request ID, endpoint, status code, and safe error message.
- Send failed permanent records to review.
- Alert when error rates rise.
Practical Example
| Error | Retry? | Action |
|---|---|---|
| 400 | No | Fix payload |
| 401 | No, not blindly | Fix auth |
| 403 | No | Fix permissions |
| 429 | Yes, delayed | Respect limits |
| 500/503 | Yes, limited | Backoff and alert |
Common Mistakes
- Retrying every error the same way.
- Retrying create actions that can duplicate records.
- Hiding failed jobs.
- Logging full secrets.
- No alert when retries fail repeatedly.
Risks and Limitations
- Retries can duplicate records if the original request succeeded.
- Not every API supports idempotency.
- Too much logging can create privacy risk.
- Silent failure queues become operational debt.
Security and Validation Notes
- Do not expose API keys, tokens, or private customer data in screenshots, frontend code, public logs, or repositories.
- Use least-privilege access and human approval for destructive actions.
- Test with safe sample data before connecting production systems.
- Monitor failures after deployment instead of assuming the first successful test is enough.
Testing Checklist
- [ ] Errors classified
- [ ] Retry rules written
- [ ] Backoff and jitter used
- [ ] Idempotency considered
- [ ] Failed queue exists
- [ ] Sensitive data masked
- [ ] Alerts active
Recommended Setup
Retry 429, timeout, and 5xx failures with limits; stop and review 400, 401, and 403 failures; and use idempotency for actions that create or change important records.
Related Systems
- 400 Bad Request API Error: Causes and Fixes
- API Rate Limit 429: Retry and Backoff Strategy
- Webhook Not Firing? Debugging Checklist
FAQ
Should every failed API request be retried?
No. Invalid requests and permission problems need correction, not retries.
What is idempotency?
It means repeating a request should not create duplicate side effects.
What should be logged?
Log safe context such as status code and request ID, not secrets.
Official documentation to check
Platform behavior can change. Before relying on this guide for a production workflow, verify current details with the relevant official documentation or primary reference below.