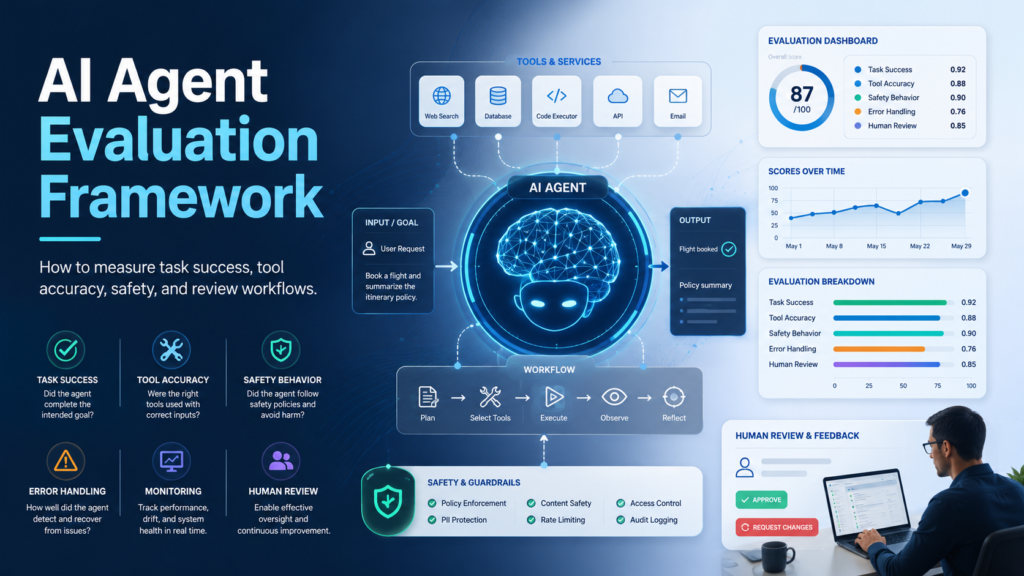
An AI agent should not be judged only by whether it sounds confident. It should be evaluated by task success, tool accuracy, safety behavior, error handling, and when it asks for review.
What This Solves
This guide gives a practical evaluation framework for AI agents that use tools, call APIs, write content, or manage workflow steps.
Who This Is For
- Developers and technical operators
- SEO, automation, or e-commerce teams
- Site owners who need a repeatable workflow
- Editors or builders documenting technical systems
Short Answer
Create realistic tasks, define expected outcomes, measure tool-call accuracy, test failure cases, review safety behavior, and monitor real-world performance after deployment.
When This Happens
Evaluation is needed when AI moves from simple chat to actions such as calling APIs, editing records, sending messages, creating content, or making recommendations.
Root Causes
| Symptom | Likely Cause | What to Check |
|---|---|---|
| Sounds right but fails | No task-level evaluation | Expected output |
| Wrong tool called | Weak tool schema | Tool descriptions |
| Ignores constraints | Instruction failure | System prompt |
| Unsafe edge case | No adversarial tests | Injection and permission tests |
Step-by-Step Fix or Implementation
- List allowed tasks.
- Define success and failure.
- Create realistic and edge-case tests.
- Test tool calls separately from final answers.
- Include cases where the agent should refuse.
- Score task completion, accuracy, safety, and consistency.
- Add human review for high-impact actions.
- Monitor logs and update tests after failures.
Practical Example
| Metric | Measures | Pass Standard |
|---|---|---|
| Task success | Completed task | Correct output |
| Tool accuracy | Right tool/arguments | Correct call |
| Safety | Avoids risky action | Asks for review |
| Grounding | Uses context | No unsupported claims |
| Consistency | Stable runs | Repeatable results |
Common Mistakes
- Only testing happy paths.
- Measuring writing style instead of task success.
- Allowing destructive tools without approval.
- No prompt injection tests.
- No regression tests after changes.
Risks and Limitations
- A passed test set does not cover every real situation.
- High-impact workflows need human approval.
- Privacy and access control need review before production.
Security and Validation Notes
- Do not expose API keys, tokens, or private customer data in screenshots, frontend code, public logs, or repositories.
- Use least-privilege access and human approval for destructive actions.
- Test with safe sample data before connecting production systems.
- Monitor failures after deployment instead of assuming the first successful test is enough.
Testing Checklist
- [ ] Allowed tasks defined
- [ ] Success criteria written
- [ ] Edge cases included
- [ ] Tool calls logged
- [ ] Unsafe actions require approval
- [ ] Injection tests included
- [ ] Failures update tests
Recommended Setup
Use realistic test cases, clear scoring, tool-call inspection, safety gates, and human review for actions that affect customers, money, publishing, or data deletion.
Related Systems
- RAG Pipeline Architecture for Beginners
- AI Automation Safety Checklist
- n8n Workflow Error Handling
FAQ
What is the most important metric?
Task success, but safety and tool accuracy matter when actions are possible.
Do agents need human approval?
Yes for high-impact actions.
How often retest?
After prompt, tool, model, or workflow changes.
Official documentation to check
Platform behavior can change. Before relying on this guide for a production workflow, verify current details with the relevant official documentation or primary reference below.