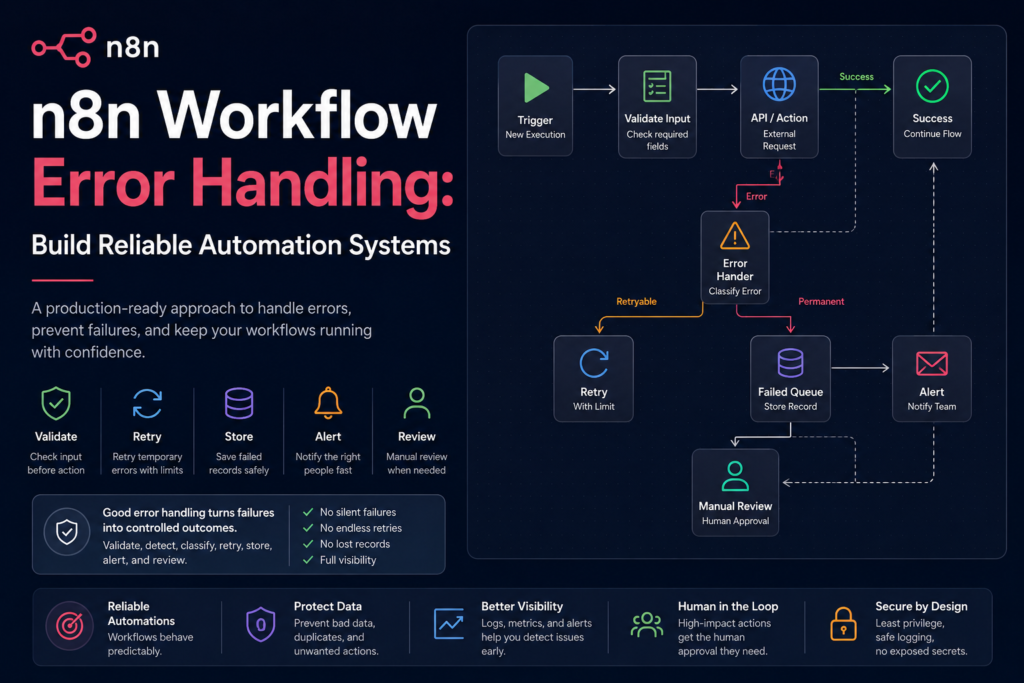
An n8n workflow should not fail silently or retry bad data forever. Good error handling validates inputs, separates recoverable errors from permanent ones, logs failures, and alerts a human when needed.
What This Solves
This guide explains a practical n8n error-handling pattern for API calls, content workflows, CRM updates, e-commerce syncs, and AI automation.
Who This Is For
- Developers and technical operators
- SEO, automation, or e-commerce teams
- Site owners who need a repeatable workflow
- Editors or builders documenting technical systems
Short Answer
Add input validation, use error branches for risky nodes, set retry limits, store failed records, send alerts, and create a manual review path for records that should not be retried automatically.
When This Happens
Workflow errors happen when input data is missing, APIs reject requests, rate limits appear, credentials expire, or downstream tools change expected formats.
Root Causes
| Symptom | Likely Cause | What to Check |
|---|---|---|
| Stops on one bad record | No per-item handling | Error branch |
| Bad request repeats | No retry rule | Error classification |
| Failures unnoticed | No alert | Notification setup |
| API rejects fields | Validation missing | Required fields |
| Duplicates created | No idempotency | Record matching |
Step-by-Step Fix or Implementation
- Identify risky external action nodes.
- Validate required fields before action nodes.
- Classify errors as retryable or permanent.
- Use retry limits for temporary errors.
- Send failed records to review.
- Add alerts for repeated failures.
- Log safe context.
- Add manual approval before publishing, deleting, or emailing.
- Review failed records regularly.
Practical Example
Trigger -> Normalize input -> Validate fields -> API/action node
-> Success path
-> Error path -> Classify -> Retry or Review Queue -> AlertCommon Mistakes
- Letting one bad record stop a batch.
- Retrying invalid data.
- No alert for failed workflows.
- Logging full secrets.
- Using admin credentials for every workflow.
- No manual approval for destructive actions.
Risks and Limitations
- Automation can scale mistakes quickly.
- Some actions should not be retried without idempotency.
- Tool UI and node behavior can change over time.
Security and Validation Notes
- Do not expose API keys, tokens, or private customer data in screenshots, frontend code, public logs, or repositories.
- Use least-privilege access and human approval for destructive actions.
- Test with safe sample data before connecting production systems.
- Monitor failures after deployment instead of assuming the first successful test is enough.
Testing Checklist
- [ ] Required fields validated
- [ ] Temporary/permanent errors separated
- [ ] Retry limits exist
- [ ] Failed records stored
- [ ] Alerts configured
- [ ] Sensitive data masked
- [ ] Manual approval exists
Recommended Setup
A production n8n workflow should have a success path, error path, failed-record queue, safe logging, and alerts. Do not rely only on the happy path.
Related Systems
- API Error Handling and Retry Logic
- AI Automation Safety Checklist
- API Rate Limit 429: Retry and Backoff Strategy
FAQ
Should n8n retry automatically?
Only for temporary errors and with limits.
What should be logged?
Record ID, node name, status code, safe error message, and timestamp.
Do I need manual approval?
Use approval for high-impact actions.
Official documentation to check
Platform behavior can change. Before relying on this guide for a production workflow, verify current details with the relevant official documentation or primary reference below.